How to Crawl a Website with MetaMonster
Learn how to use MetaMonster's crawler to extract SEO data from your website. Discover full site crawls, CSV uploads, and what data is collected during the crawl process.
All projects in MetaMonster start with a site crawl. This guide shows you how to use the crawler to get your site content into the platform.
Two ways to crawl
You have two options for crawling your site:
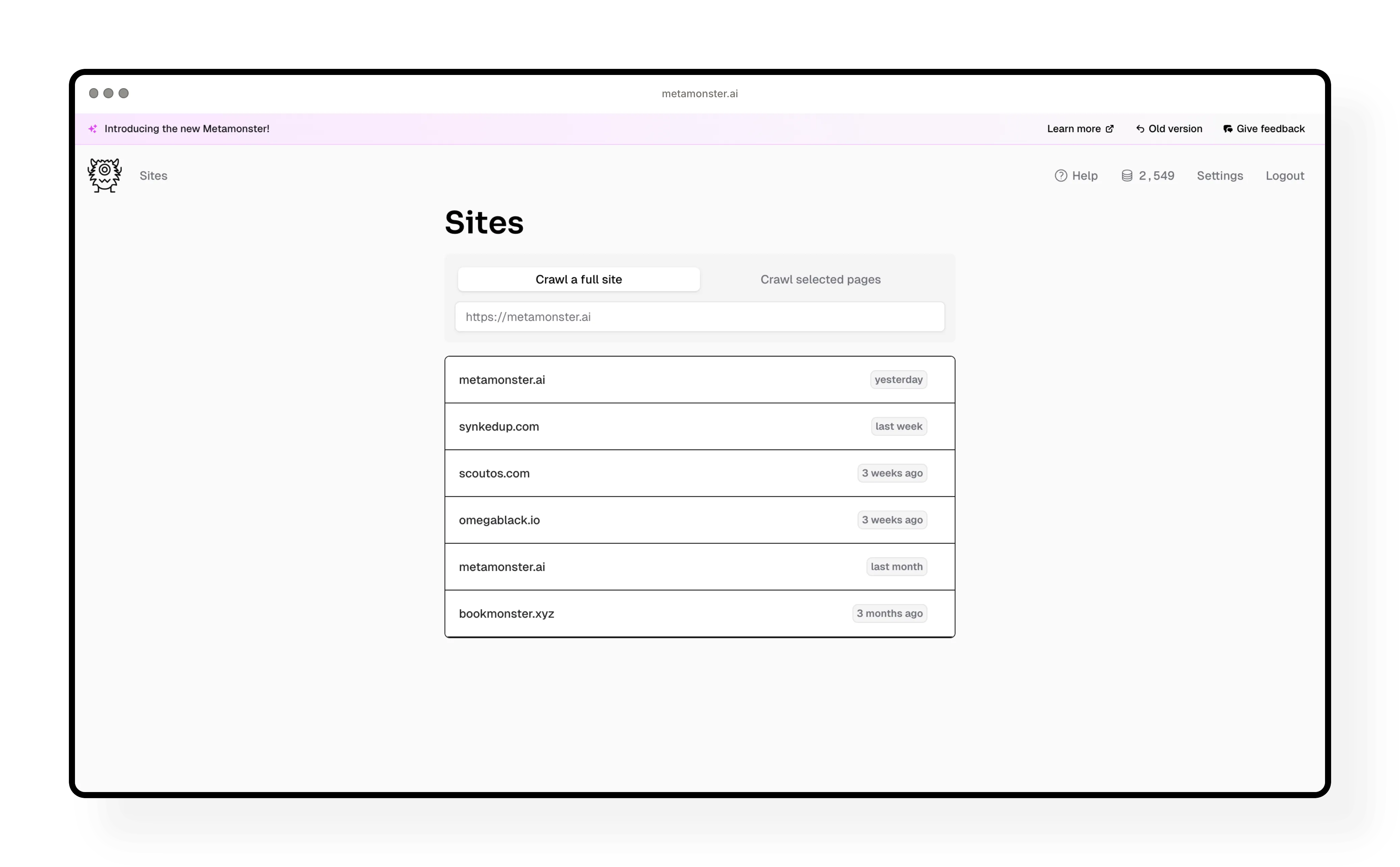
Full site crawl: Enter your domain and MetaMonster will automatically discover and crawl all pages on your site.
Selected pages crawl: Upload a CSV containing only the URLs you want to crawl. Perfect when you want to focus on specific pages.
Limiting the number of pages
You can set a limit on how many pages the crawler will discover. This is useful when:
- You have a really big site and want to start with just a subset
- You’re testing MetaMonster and want to get started quickly with a few pages
Important note: Crawls do not count against your credit limits. The page limit is just for managing the size of your initial dataset, not for saving credits.
What happens during a crawl
Once you click “Start crawling,” MetaMonster automatically handles:
- JavaScript rendering - Turned on by default to capture content from modern sites
- Anti-bot detection - Built in so you can crawl without issues
- Markdown conversion - HTML is converted to markdown, which is easier and faster for AI to parse
- Vector embeddings - Generated automatically for semantic searches and content analysis
No extra configuration needed - everything happens out of the box.
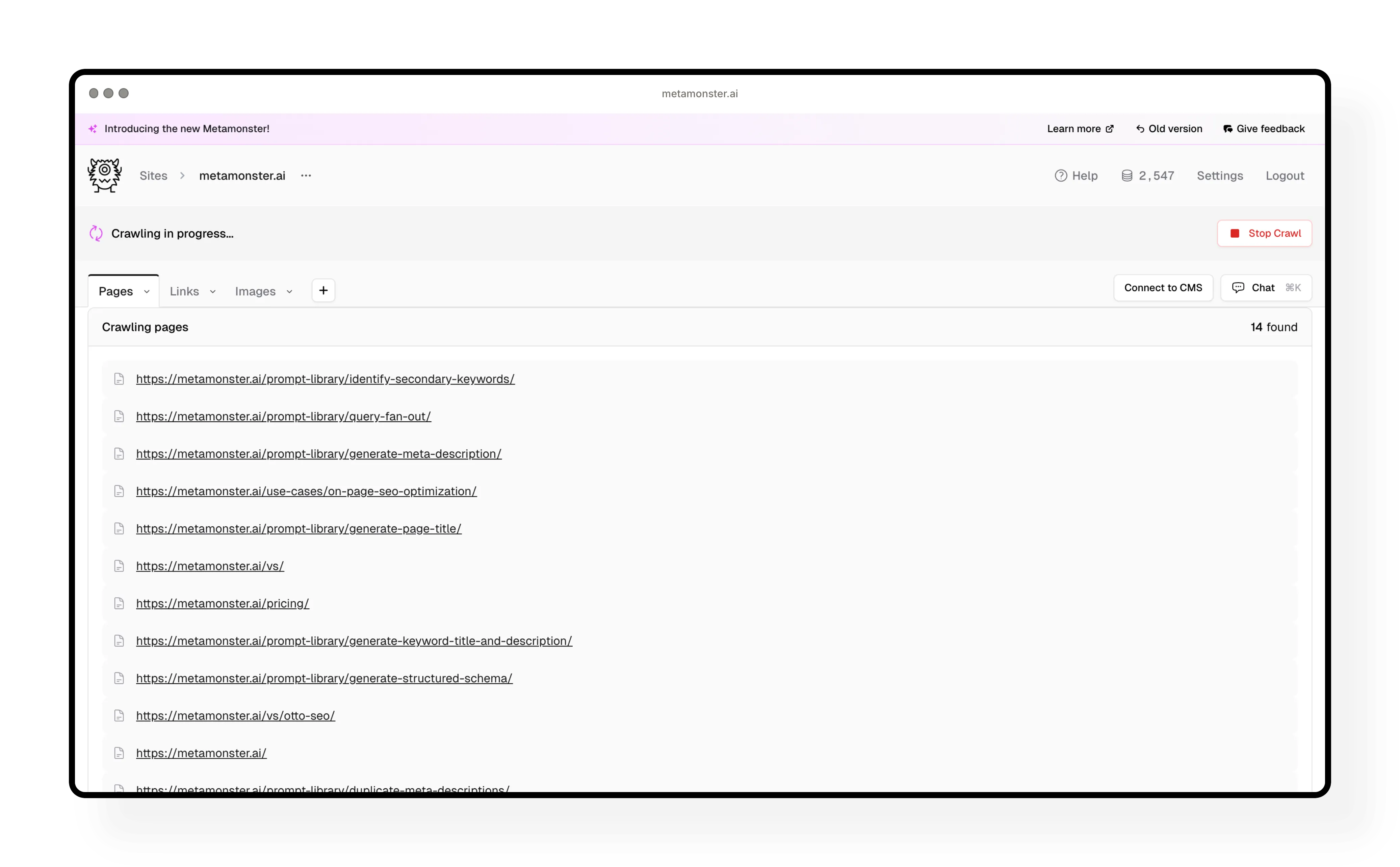
Stopping a crawl early
You can click “Stop crawl” at any time. The crawler will stop wherever it is and give you everything it’s crawled so far.
Example: You’re testing MetaMonster for the first time, you’ve crawled 100 pages, and you decide that’s enough to start working with. Just hit stop crawl and you’re ready to go.
Reviewing your crawl results
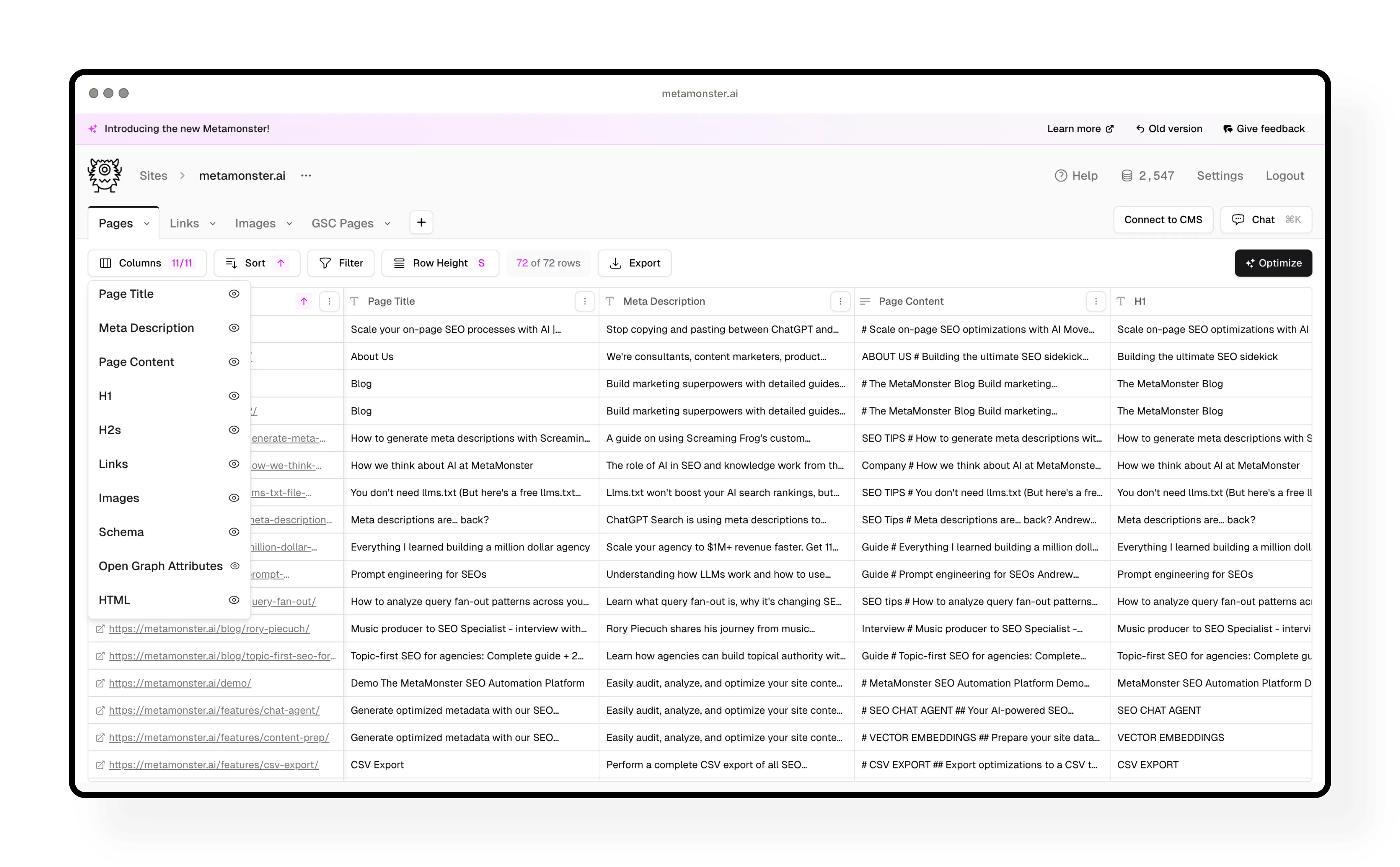
After your crawl finishes, you’ll see all your pages organized in a table. Each page includes these extracted elements:
- URL
- Page title
- Meta description
- Page content (converted to markdown)
- H1s and H2s
- Links
- Images
- Schema markup
- Open Graph attributes
- Raw HTML
Working with the data: You can view everything right in the table. Multi-item fields (like images or links) are listed out with preview mode, or you can view the raw JSON if you need it.
Additional tabs
MetaMonster also creates two extra tabs for you:
Links tab: All your links organized by destination type, anchor text, and the page they’re linking to.
Images tab: All images across your site, organized with their URLs and alt text. This is handy when you want to generate alt text for all images at once without going page by page.
Crawling with a CSV
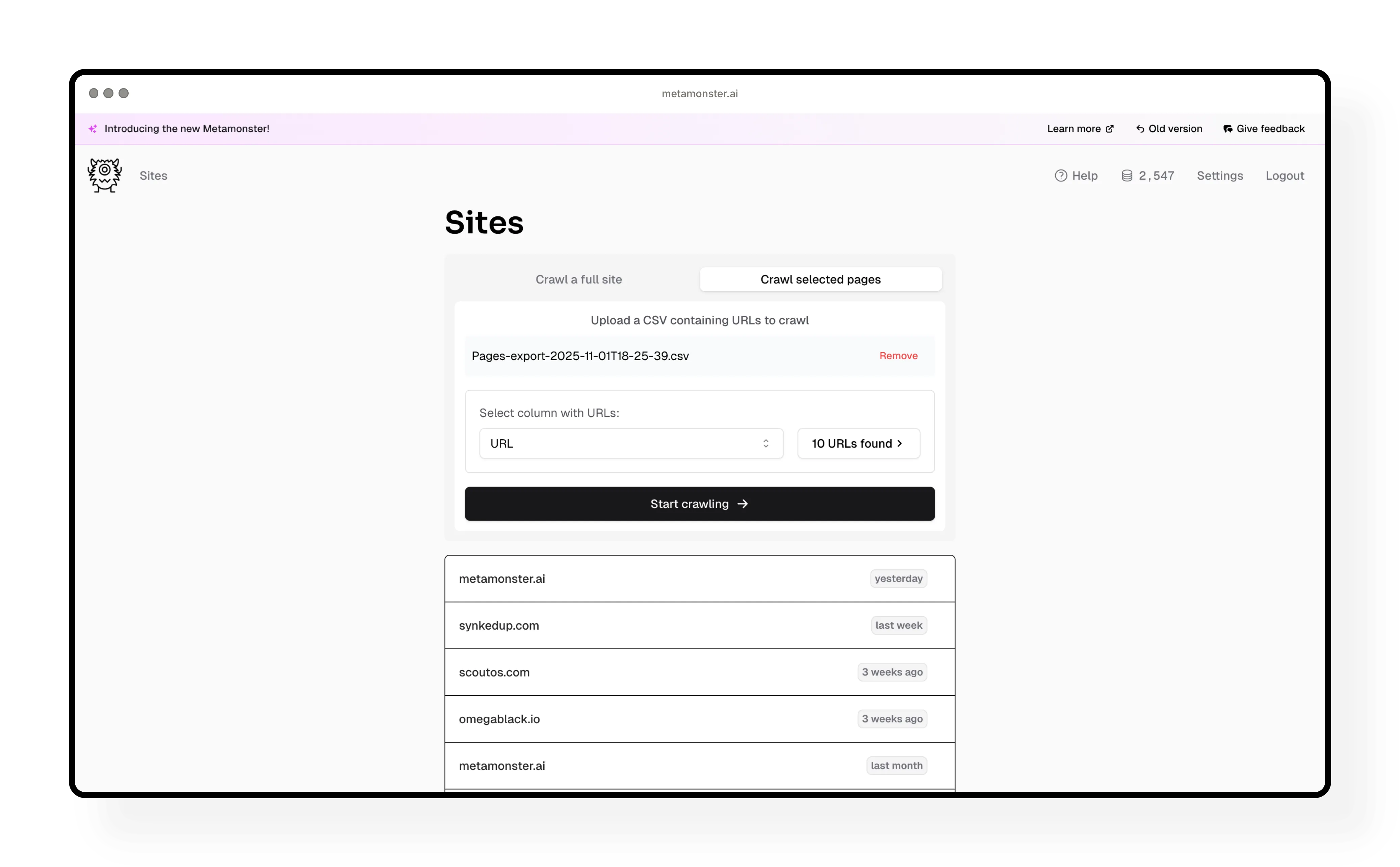
The process is nearly identical when using CSV upload:
- Prepare a CSV file with your URLs (just needs a URL column)
- Upload the file to MetaMonster
- Confirm the number of URLs found
- Select which column contains your URLs
- Click “Start crawling”
The crawler still uses JavaScript rendering, anti-bot detection, and generates vector embeddings and markdown - just like with full site discovery.
What’s next
Once your crawl is complete, you’re ready to start optimizing. Check out the Getting Started with MetaMonster guide to learn the full workflow from crawling to exporting optimizations.
Need more help?
Can't find what you're looking for? Email us at support@metamonster.ai or chat with our team.